For T-SQL Tuesday #186, Andy Levy asks, “How do you manage and/or monitor your SQL Server Agent jobs?”
This is a great opportunity for me to discuss how DBA Dash can help monitor SQL Agent jobs. DBA Dash is a free and open-source monitoring tool for SQL Server, created by me. It’s used to monitor thousands of SQL Server instances within Trimble alone, and it’s gaining popularity in the SQL Server community.
Built-in alerts for job failures
Before we discuss DBA Dash, what can we do within SQL Server without any 3rd party tools?
SQL Agent jobs have native alert notifications. You can get an email whenever a job fails, succeeds, or completes.
Issues with built-in alerts:
If a frequently executed job starts failing, this can generate a lot of noise. A workaround is to set a retry policy and retry interval for your job steps.
A lack of a failure notification doesn’t mean that everything is in a good state. You should validate the status of your SQL agent jobs in combination with alerts. Job activity monitor in SSMS could be used for this, but it doesn’t scale if you have many SQL instances to monitor.
It requires database mail. There are no modern notification channels like Slack, Google chat, PagerDuty etc.
DBA Dash
DBA Dash includes several useful features to help you monitor your SQL Agent jobs.
Summary page
First up is the summary page. This is a single-page report that can tell you if you have failing jobs across your whole SQL Server estate. It can also tell you if your SQL Server agent is stopped on any of those instances. The summary page includes many other things you should include as part of your daily checks, in addition to monitoring agent jobs.
From the summary page, you can drill down and see specific jobs that are failing across your instances. You can click to view the failed steps and messages.
Thresholds and exclusions can be configured at the root, instance or job level.
Alerts
DBA Dash has an AgentJob alert rule that you can use for instant notifications. You can target a specific server, a group of servers (using tags), and filter by category and job name. Your notification options currently include Email, Slack, PagerDuty and Webhook (e.g. Google Chat).
This provides more modern notification options over built-in alerts and allows alerts to be configured centrally. You can control when you are notified and by what mechanism, depending on the priority of the alert.
Job Performance
You might also be interested in tracking job performance over time. DBA Dash allows you to do this centrally. The msdb database maintains a history of job execution, but the DBA Dash repository database enables you to store the execution metrics for a long time with minimal storage cost. You can also visualize the job performance over time very easily.
Timeline
The timeline view is a great way to see which jobs ran when and how long they ran for. This is useful to help plan job schedules, among other things.
Running Jobs
Want to know what jobs are running right now across all your instances?
Schema Tracking
DBA Dash scripts your SQL agent jobs, tracking when changes occur. This can be used to help answer what changed when and provides access to previous versions of jobs, should you need to roll back.
If you can source control your SQL agent jobs, that is also a great idea. DBA Dash can complement that.
This feature is also used to provide a SQL agent job DIFF tool so you can compare jobs between SQL instances.
More to come
As I’m writing this, I’m working on a Job Info page to provide job details on a single page (Steps, schedules, and other metadata). I’m using ScriptDom to parse this information, and with the DDL tracking, I can display this info for past versions of a job. I can also use this to display an alternative DIFF format.
DBA Dash includes a Running Query capture for performance monitoring (similar to sp_WhoIsActive or sp_BlitzWho). This will show you the job name if a query is associated with a running job. In the next version of DBA Dash, this will be a link, providing you with immediate access to the job details and execution stats.
These features should make their way into the next version of DBA Dash, 3.23. Or they might already be available by the time you read this.
In SQL Server, the sp_delete_backuphistory stored procedure is is the standard and supported method to purge old data from the backup and restore history tables in the msdb database:
backupfile
backupfilegroup
backupmediafamily
backupmediaset
backupset
restorefile
restorefilegroup
restorehistory
Recently, I encountered an issue running sp_delete_backuphistory on servers that hosted a large number of databases with frequent log backup & restore operations. The clean up task hadn’t been scheduled and the history tables had grown very large over several months. The msdb databases was also hosted on a volume with limited IOPs.
Attempting to run sp_delete_backuphistory under these conditions you will likely encounter these issues:
The operation will take a long time
Log backup and restore operations are blocked during the process
Your msdb log file will grow large if you try to remove too much data at once
If you kill off the process at any point, the whole thing will rollback.
The sp_delete_backuphistory stored procedure gets the job done in most cases but it’s not very well optimized if you have a large amount of history to clear.
Optimized Solution for Backup History Cleanup
To clear a large amount of history without resorting to schema modifications or unsupported methods we can take an incremental approach to removing data.
The script below will check how much retention we currently have. It will then call sp_delete_backuphistory in a loop, removing data 1hr (configurable) at a time until we hit the target retention. We can also specify a maximum runtime for the process.
This approach won’t necessarily speed things up but it provides the following benefits:
Data is cleared as a series of smaller transactions rather than a single large transaction
Smaller transactions allow for log truncation and prevent the log file from growing.
We can interrupt the process without having to rollback all the progress that has been made. (just the current batch)
Log backups/restores might still be blocked, but only for the duration it takes to complete a single loop – not for the entire time it takes to clear the history. This can still impact RPO/RTO though.
We can control how long the process runs for. We can keep it running outside business hours or allow for breaks to prevent log backup/restores from falling too far behind.
The invitation from Tom Zíka asks “Which quality makes code production grade?“.
Reliability
Code that runs in production should be reliable. It should produce consistent results, handle concurrency and deal with error situations.
Performance & Scalability
Production code needs to be able to scale. Scalability should be considered in the context of your own applications and their expected growth. Not everyone has to deal with the same scalability challenges as Google, Facebook or Twitter.
Performance is also important. It doesn’t matter how awesome your app is if it can’t return data fast enough for end users.
Fast and efficient code can save $$$ in running costs and keep end users happy.
Security
Production code needs to be secure, following industry best practices. A security incident can cause severe reputational damage and financial impact.
Maintainability
Production code should be maintainable. Avoiding duplication and striving for simplicity.
Reviewed
Production code will often go through a code review by another developer before it’s accepted into the codebase.
Tested
Production code will go through a series of automated and human tests before it gets to production.
Accurate?
Production code doesn’t always have to produce accurate results. Accuracy can be very important in some situations. In others, you might be able to trade some accuracy for speed. e.g. Caching data, eventual consistency. The number of active users on a website doesn’t need to be 100% accurate and can be out of date by the time it’s printed.
Documented
Production code should have comments and documentation.
Other
You might have policies for coding standards to follow. This might include things like naming conventions, code formatting and other best practices.
Does it need to be perfect?
Production code doesn’t have to be perfect. Perfect code doesn’t really exist. The code we write today will be viewed through a different lens tomorrow with the benefit of hindsight, experience and new improved ways of doing things.
The code we ship to production needs to be fit for purpose. Shipping code that works and delivers value in a timely manner is often more important than spending months trying to find the most optimal solution. There is a balance to be struck.
Architectural decisions made early in a project can have long-lasting consequences. Making good decisions early in a project can be cheaper than fixing them later.
You can’t always predict how users will use a new feature and how to optimize it. Growing pains are inevitable for successful applications. It’s important to monitor and be proactive in fixing problems.
Not production grade
So what are some examples of code that shouldn’t be in production?
Code that uses undocumented/unsupported features or behaviour
Untested code
Insecure code. e.g. Building dynamic SQL in a way that is prone to SQL injection.
Summary
Production code can vary in quality for a variety of reasons. The experience level of the developer writing the code, time pressures, and level of fatigue all impact code quality.
It’s not unusual for code written as a quick PoC to find its way into production. Code can also start to get messy over time as you start to shoehorn new features into an existing codebase.
If your code is delivering value to the end-user or business you can feel happy about it. Over time we all accumulate technical debt and need to allocate time to reduce it.
The first public release of DBA Dash was in January 2022 and version 2.21.0 is the 24th release.🎉 A lot has changed with many new features added as well as bug fixes. I haven’t really blogged much about the changes, but I thought it might be good to capture what its new for significant releases. So here is what is new and cool in 2.21.0!
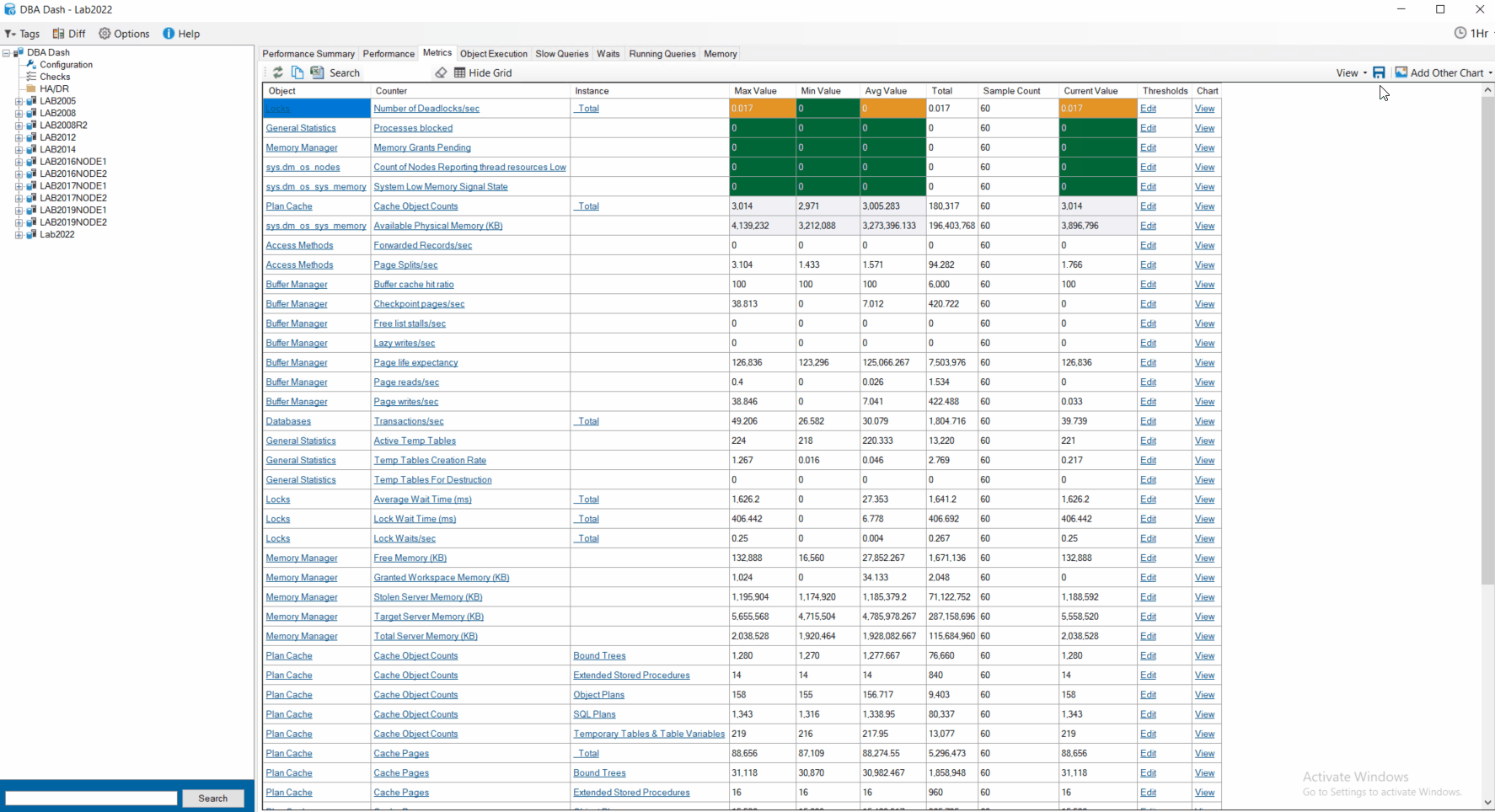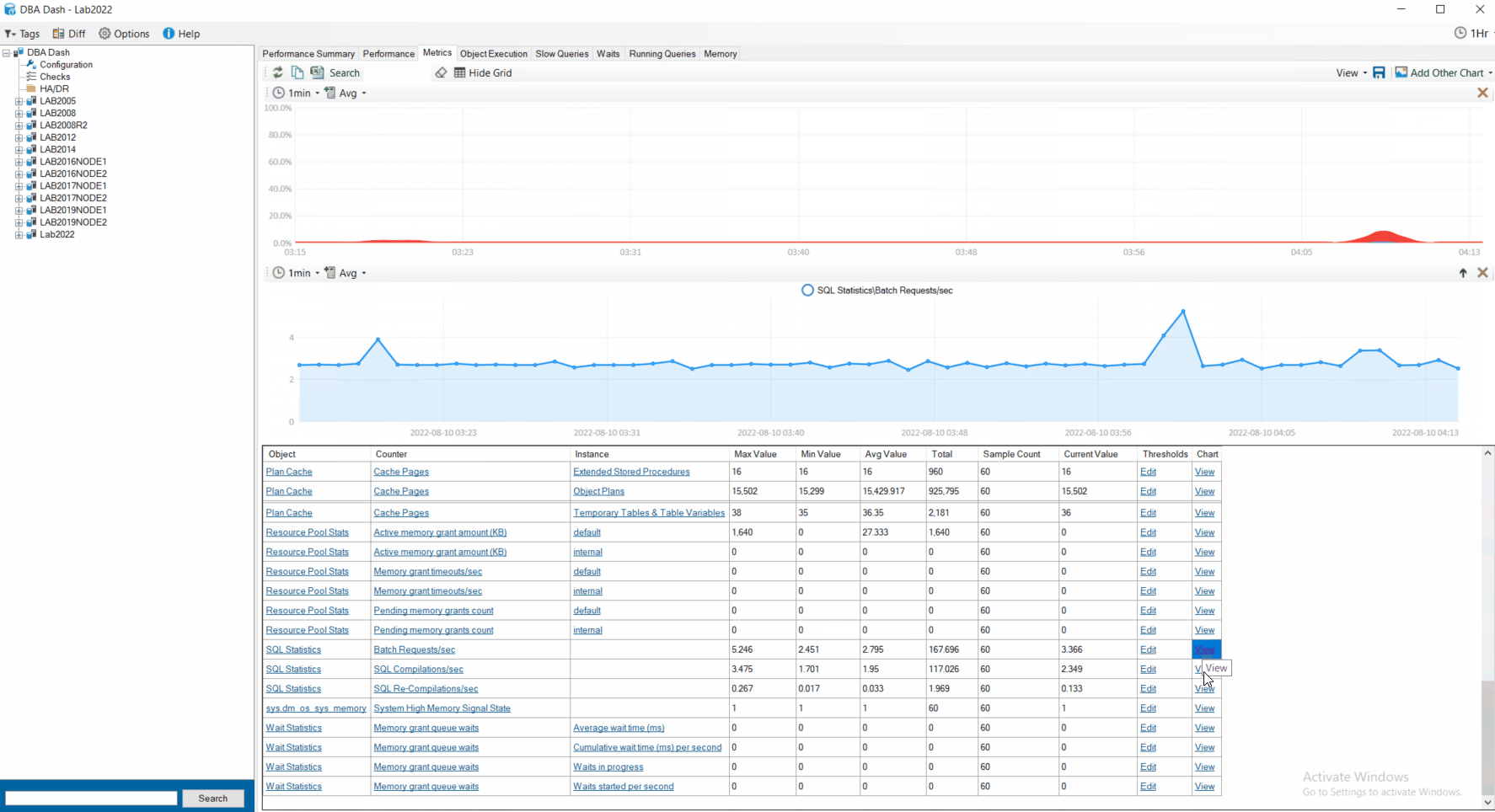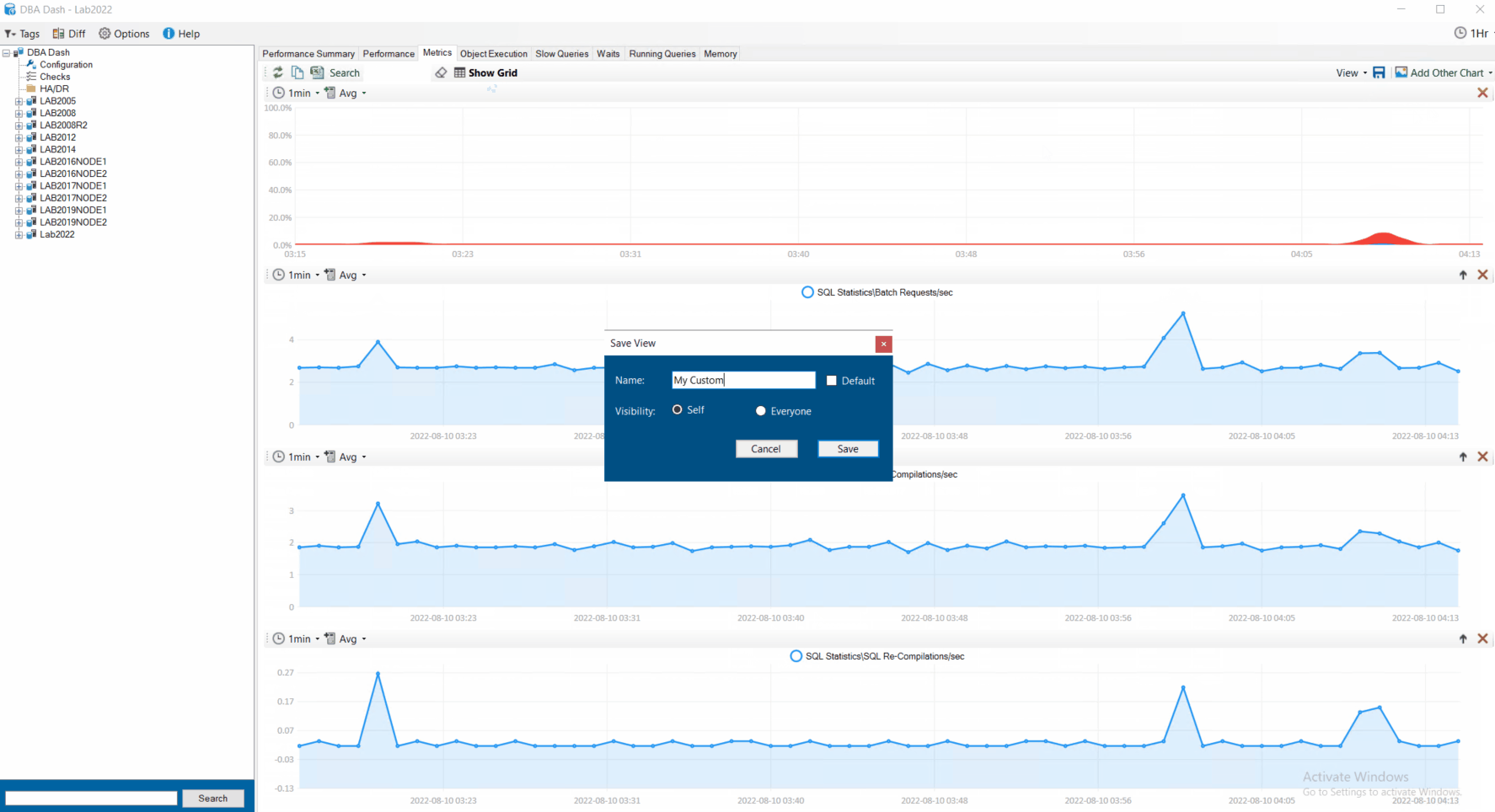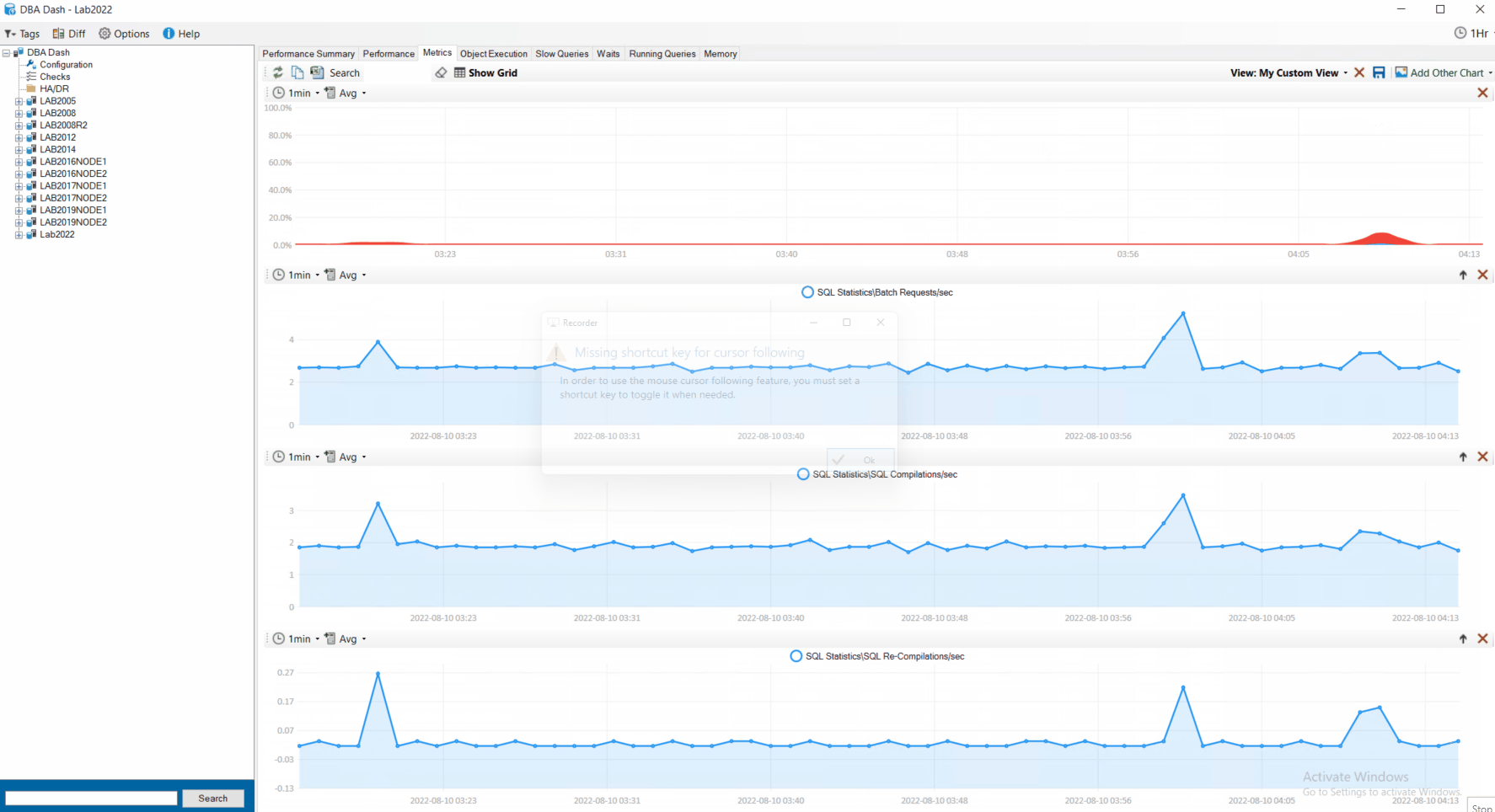
The metrics tab was previously a wall of numbers – the Max, Min, Avg, Total & Current value of all the collected performance counters. At the click of a button you could see a chart for any counter over time for the selected period. It was limited to showing 1 chart at a time.
In 2.17.0 it was possible to configure threshold values for your counters – improving on the wall of numbers by highlighting counters that need your attention.
Now in 2.21.0 when you click view to view a chart for a particular counter, it adds a new chart. You can view charts for multiple counters simultaneously. Also, you can add other charts that are not os performance counters – CPU, Blocking, IO, Object Execution and Waits. This provides additional context for your performance counters. You can re-order the charts and remove them at the click of a button.
Once you’ve created a useful dashboard you can save and re-load it at the click of a button. You can save the view for yourself or share it with your team.
Tip: You can easily configure which performance counters are collected. Also, you can collect any metric you like that can be queried with T-SQL. See here for details on how to customize the collection.
Performance Summary tab
The performance summary tab now has saved views the same as the metrics tab. You could save the layout previously but it wasn’t possible to save multiple versions or to share those with the rest of the team.
sp_WhoIsActive and sp_BlitzWho are popular stored procedures created by the database community. They both capture queries currently running on your server. If you are a seasoned DBA it’s likely you have come across one or both of these tools. sp_WhoIsActive in particular has been around for a very long time, deployed to many, many thousands of servers. It’s helped me solve countless performance issues. Shout out to Adam Machanic who created the tool – Thank you!
The Brent Ozar team created sp_BlitzWho due to licensing issues distributing sp_WhoIsActive. The licensing issues are no longer a concern as both tools are now open source and can be freely distributed. sp_BlitzWho still has a more permissive license but the difference isn’t likely to matter to most people. Both work great. Each has unique selling points. Include them on all your SQL Server deployments! The excellent dbatools can help with that.
DBA Dash isn’t a stored procedure for showing active queries – it’s a full monitoring tool with a Windows app front end. So this is a bit of a weird comparison. It does capture running queries though which is where we can draw some comparisons.
Re-inventing the Wheel
While developing DBA Dash I did consider just embedding sp_BlitzWho or sp_WhoIsActive rather than re-invent the wheel. Licensing was maybe a concern for sp_WhoIsActive but I had other reasons for creating my own solution. I wanted a solution designed specifically for regular collection. sp_BlitzWho and sp_WhoIsActive can both log to a table. But they were designed for interactive use in SSMS.
Performance
The goal for DBA Dash was to limit the overhead of query collection. Also, I did not need or want the data to be formatted for human consumption on collection. The numbers below show a performance comparison. I’m using the defaults for each and averaging over 10 executions. 12 active queries were running for this test.
Tool
Avg CPU (ms)
Avg Duration (ms)
sp_WhoIsActive
159
166
sp_BlitzWho
231
241
DBA Dash (with session waits)
6
15
Performance Tests
Note: I don’t worry about the overhead of running any of these tools interactively. Also, if you want to log the output to a table at regular intervals it’s not likely to hurt the performance of your server. Still, for regular monitoring, it’s good to keep overhead as low as possible.
If you want to test this for yourself, the capture query for DBA Dash is here. Confession time – this isn’t a fair fight. I’m not collecting query text or query plans. sp_BlizWho collects query plans by default so it’s at a disadvantage – the tools are not all doing the same thing. Also, the performance differences between these tools will vary based on several other factors.
So how does DBA Dash show query text?
Takes a distinct list of sql_handles from the running query capture
Collect text associated with those handles (if required).
Cache the handles.
Ignore the handles we’ve already captured on subsequent collections.
Query plan capture features a similar optimization. Also, DBA Dash doesn’t need to do anything with the formatting of the data for human consumption – at least not on collection.
Query text and query plans are stored in separate tables. Not duplicated by row. DBA Dash can also take care of data retention – clearing out old data efficiently with some partition switching.
This isn’t just about efficient data collection. DBA Dash has a custom GUI and isn’t bound by the same constraints as sp_WhoIsActive and sp_BlitzWho. This allows us to do some interesting things.
Summary Data
At the top level, we see the summary of the last running queries snapshot for each instance. In this case, we can see some serious blocking going on with instance DASH2019.
From there we can drill down to the DASH2019 instance and see a list of recent snapshots. We can also go back in time to any custom date range and see a list of the snapshots collected.
Use the summary data above to determine which snapshots are most interesting. Then drill down to the individual snapshots themselves:
Blocking
In the screenshot above I’ve zoomed into the blocking section of the report. DBA Dash highlights the sessions blocked in the “Blocking Session ID” column. In some cases, there will be long blocking chains. This can make it difficult to work out which is the root blocker by looking at the blocking session id and traversing the blocking chain manually. With sp_WhoIsActive you can pass @find_block_leaders=1 to make this easier which gives you a blocked session count.
With DBA Dash you can just look at the “Blocking Hierarchy” column. Take session 64. This is blocked by session 79 and we have a hierarchy of “90 \ 79”. Session 79 is blocking the current session 64. Session 90 is blocking session 79 and is our root blocker. The “Root Blocker” column also identifies which sessions are root blockers. You can filter to show just the root blockers at the click of a button.
The “Blocked Count” column shows how many queries are blocked directly by a session. You also have a “Blocked Count Recursive” column that shows you a total count of sessions blocked by the query (directly/indirectly). The counts are also clickable – allowing you to navigate the blocking chain interactively.
So what’s actually going on in this snapshot?
DBA Dash identifies session 90 as the root blocker. Session 90 isn’t blocked or waiting on anything. The CPU time and reads are very small. The status column is “sleeping” and we should pay close attention to this. A sleeping session is dormant – waiting for input from the app. This is a problem if the session has an open transaction – holding locks needed by other sessions. DBA Dash gives us the user, hostname, application name along with the query text that will assist in tracking this down.
The root cause of this issue is an update statement that ran from SSMS. It had a BEGIN TRAN but didn’t issue a COMMIT or ROLLBACK. This left the transaction open, holding locks that caused the blocking.
Sleeping sessions causing blocking are something to watch out for. It might indicate problems that need to be fixed in the app. e.g. Not using the “using” pattern, doing slow work in the middle of the transaction like calling a web service.
Waits
DBA Dash shows what queries are currently waiting on. It also captures the wait resource and parses the wait resource to make it easier to decipher. Session level waits are also available in DBA Dash (and sp_BlitzWho). DBA Dash extends this by providing a clickable link that will show the session level waits in table format with more detail.
Text
DBA Dash gives you the statement text and the full query text associated with the SQL handle. Just click the links in the grid to see the text formatted in a new window.
Plans
DBA Dash can show you query plans at the click of a button. Configure this using the service configuration tool. The collection process is optimized the same as for query text. Also, you can reduce the cost of collection further with plan collection thresholds.
A query plan tells you exactly how SQL Server was attempting to process the query. It also gives you the parameters that were used to compile the query plan.
Batch Completed / RPC Completed
Having the batch text and statement is great. For a typical RPC call, we can see the current statement along with the text of the associated stored procedure (or batch). What’s missing are the parameter values passed in from the client application. Unfortunately, we can’t get this by querying the DMVs. DBA Dash has a trick up its sleeve though. We can enable the capture of slow queries which creates an extended event session to capture queries that take longer than 1 second to run (configurable).
What’s cool is that you can click a session ID in running queries and see the associated RPC/batch completed event. This gives you the metrics associated with the completed execution and also the query text with the parameter values. Having the parameter values is useful when trying to reproduce and diagnose performance issues.
Note: The associated RPC/batch completed event is only available if the query has completed. It also needs to meet the threshold for collection. DBA Dash collects this data every 1min by default which adds additional delay. For the most recent snapshot, you might need to wait before the RPC/batch completed event is available.
Full Duplex
The link between running queries and RPC/batch completed is two-way. The Slow Queries tab shows you the RPC/batch completed events captured from the extended events session. From here you can click the session id and see all the running queries snapshots captured for that session while the query was running. Having access to the running queries snapshots can help answer questions about why a query was slow. e.g. Was it blocked? What was it waiting for? What was the query plan used? What statement was running?
Note: For queries with shorter execution times you might not have any data as running queries is captured every 1min by default.
Grouping and Export
You can group the running query capture in DBA Dash with the click of a button. For example, you might want to count the number of running queries by application, query hash, hostname….lots of options here. From there you can drill down to see the queries associated with your selected group value.
Exporting the data to Excel is also just a click away.
Not a GUI person?
The captured running query data is available in the DBA Dash repository database for you to query manually if required. I’d recommend using the dbo.RunningQueriesInfo view. The application calls dbo.RunningQueries_Get to return a specific snapshot (which uses the view).
Wrap up
Running queries capture is just a small (but interesting) part of what DBA Dash can do. There is a lot more that the tool can do – pair DBA Dash with query store and you have a lot of bases covered.
sp_WhoIsActive and sp_BlitzWho still have a place in my toolbox. I use them often. They are great tools and DBA Dash doesn’t replace them. I’m, running these tools interactively where DBA Dash is capturing valuable performance data round the clock for both current and retrospective analysis.
There is a lot of value in running a quick command in SSMS and having the results available immediately – in the same tool. With DBA Dash you have to wait for the next scheduled collection which is every 1min by default. Also, not everyone will want a full monitoring tool just to capture running queries. sp_WhoIsActive and sp_BitzWho both have their unique selling points and DBA Dash doesn’t replicate all their features and functionality.
If you haven’t tried DBA Dash, it’s a free monitoring tool for SQL Server that I created. My employer Trimble has allowed me to share the tool open source and it’s available on GitHub here. sp_WhoIsActive and sp_BlitzWho are also open source. Give them a try today.
There are a few methods you can use to get drive information using T-SQL. The problem is all these methods have some limitations. They provide free space but not drive capacity or they only provide data for volumes that contain database files. Ideally Microsoft would provide an easy way to get both drive capacity and free space for all drives. In this article I’ll demonstrate a way to do this using T-SQL.
Here are a few exiting methods that you might consider before we continue:
Get drive information using T-SQL
Transact-SQL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
-- Gets size and free space but only for volumes that have SQL data files.
If these work for your needs, great! If you need capacity and free space for ALL drives you will need a different solution. The best option might be to query that data outside of SQL Server using PowerShell or your programming/scripting language of choice. If you need to do this in T-SQL though, the script below provides a way.
The script uses xp_cmdshell to run a powershell command to get data for ALL the volumes on your system. Powershell formats this data as XML which we capture in the @output table variable – 1 row per line of XML. Then we convert this back to a single string and store as XML in variable @x. We then shred the XML into a table format. This is a bit of a hack – sys.dm_os_volume_stats is a cleaner method but doesn’t give you data for all drives. As a bonus you get more detailed data about those drives; file system, allocation unit size & more.
A similar technique could be used to capture the output of other powershell commands in T-SQL. It might not be a good idea but I think it is an interesting technique to demo.
When you configure your SQL servers for high availability you want the failover to be as seamless as possible. If you use availability groups, mirroring or log shipping as part of your high availability strategy you will need to take care of anything that lives outside the context of your databases. That might include logins, SQL Server agent jobs and ensuring consistent server level configuration across your availability nodes. This article will discuss how to handle SQL server agent jobs.
Not so seamless failover of agent jobs
If you have any SQL agent jobs that run in the context of your user databases these will need special handling to ensure a seamless failover. Ideally Microsoft would have added some improvements to the SQL agent to help with this. Maybe given us agent jobs that can live within the context of a user database instead of msdb?
As it stands you will need to keep your agent jobs in sync between the primary and secondaries and figure out a mechanism to activate the jobs on the new primary following failover and disable them on the old primary.
A Solution
There are a few ways to handle this, but my approach is to run all the jobs in the context of the master DB. I then check if the user DB is accessible and execute the command with a 3 part name. See the script below for an example. This will work for availability groups, mirroring and log shipping.
With this approach you can create your jobs and have them active on your primary and secondaries. You don’t need to worry about enabling/disabling jobs on failover – the jobs are already running but they only do any work if the database is primary. This makes the failover totally seamless. The downside to this approach is that the jobs will report that they ran successfully even if they didn’t do any work which could cause confusion.
The next problem is keeping the jobs in sync between your servers. You can script out the jobs using SSMS easy enough but this could get tedious if you have a larger number of jobs. I’ve created a powershell script below to help with this which you can use below. You can use this to report if your jobs are out of sync and also for performing a synchronization. See the comments at the top of the script for some usage examples.
SyncSQLAgentJobs.ps1
PowerShell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
Param(
[Parameter(mandatory=$true)]
[string]$ServerA,
[Parameter(mandatory=$true)]
[string]$ServerB,
[Parameter(mandatory=$false)]
[System.Array]$ExcludedCategories=@(),#Job categories to exclude from the synchronization process.
[Parameter(mandatory=$false)]
[System.Array]$IncludedCategories=@(),#Job categories to include in the synchronization process.
[Parameter(mandatory=$false)]
[switch]$DoSync#perform a two way synchronization if specified, otherwise run in reporting mode.
)
<# Created: 2017-12-06
Author: David Wiseman
Description: Sync agent jobs between two SQL Server instances or check synchronization status. This is useful if you are using a high availability technology like
availability groups, log shipping or database mirroring that does not include SQL Agent jobs in the failover. The script can be used to validate that the jobs are in sync
Any jobs that don't exist will be copied from SERVER1 to SERVER2 and from SERVER2 to SERVER1. Any jobs that are different will be copied from the server with the newer version of the job (Based on DateLastModified).
This will ensure the job fails if anything is out of sync. The SQL Server agent account will need appropriate access to msdb database on both instances.
























{kind=link}